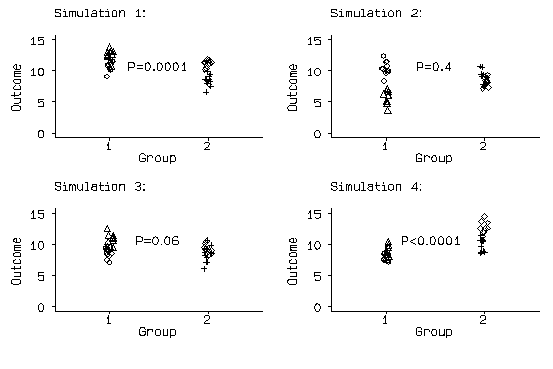按:90%以上的医学随机对照研究都是cluster randomised trials.许多人在试验结果的统计分析上范错误。Martin Bland 是世界上著名的生物统计学家,看看他怎莫说。下面是他在British Medical Journal 上发表的文章。希望对医学科研工作者有些帮助;同时给EBM工作者提供一个评鉴论文的tool. 因为字数限制,我大幅删节了文章. For more details, please refer to:http://www-users.york.ac.uk/~mb55/talks/clusml.htm
Cluster randomised trials in the medical literature Martin Bland,
Dept of Health Sciences,
University of York
Published (in part) as: Bland JM. (2004) Cluster randomised trials in the medical literature: two bibliometric surveys. BMC Medical Research Methodology 4, 21. Talk first presented to the RSS Medical Section and RSS Liverpool Local Group, 12 November 2003. Abstract If a cluster-randomised trial is analysed without recognition of the clustering, the analysis will ignore the possible correlation between members of the same cluster. When positively correlated observations are treated as independent, the result may be standard errors which are too small, confidence intervals which are too narrow, and P values which are too small, leading to conclusions which may be false. I shall describe the analysis of some published trials and give a biased and partial review of the history and current situation. Cluster designs Cluster designs are those where research subjects are not sampled independently, but in a group. They can be experimental, such as a trial where all the patients in a general practice (primary care provider) are allocated to the same intervention, the general practice forming a cluster. They can be observational, such as a study where several towns are selected and then people are chosen for interview within those towns, the people in the town forming a cluster. In this talk I shall consider only experimental designs. In either case, members of a cluster will be more like one another than they are like members of other clusters. We need to take this into account in the analysis, and preferably the design, of the study. Methods which ignore clustering may mislead, because they assume that all subjects are independent observations. This is not the case in a cluster design, because observations within the same cluster are correlated. If we apply simple statistical methods to such data, without taking the clustering into account, this may lead to confidence intervals which are too narrow and P values which are too small.
I shall state at the outset that I have in past ignored clustering in the analysis of clustered designs. I suspect that many medical statisticians have done the same. A simulation of the effects of clustering If P values are too small, we will detect differences where none exist more frequently than the 5% of tests which we expect to be significant when the null hypothesis is true. To illustrate this effect I carried out a little simulation. I generated four cluster means, two in each group, from a Normal distribution with mean 10 and standard deviation 2. I then generated the 10 members of each cluster by adding a random number from a Normal distribution with mean zero and standard deviation 1. Thus the null hypothesis, that there is no difference between the means in the two groups, is true. I then carried out a two-sample t test comparing the means, ignoring the clustering. The results of the first four simulations are shown in the following figure: d Figure 1. Simulation of a small cluster-randomised trial, first four runs. The first difference is highly significant, with the mean in group 1 exceeding the mean in group 2, and the fourth is highly significant, but the means are the other way round. I ran this simulation 1000 times and obtained 600 significant differences with P<0.05, of which 502 were highly significant, with P<0.01. If the t test ignoring the clustering were a valid test, we would expect 50 significant differences, i.e. 5% of 1000, and 10 highly significant ones. The reason for this is that the analysis assumes that we have 20 independent observations in each group. This is not true. We have two independent clusters of observations, but the observations in those clusters are really the same thing repeated ten times. This is fairly obvious in the figure: d This makes the standard deviation smaller than it should be, and the number of observations larger than it should be, which makes the standard error smaller than it should be, which in turn makes the t statistic bigger than it should be. It also makes the degrees of freedom bigger than it should be. These combine to make the P value smaller than it should be. My simulation is very extreme, with two groups of two clusters and a very large cluster effect. However, I have been a referee for a grant proposal for a cluster randomised trial with two groups of two clusters, and a smaller cluster effect would only reduce the shrinking of the P values, it would not remove it. The simulation shows that spurious significant differences can occur if we ignore the clustering. When P values tend to be too big, and we miss significant difference, we don't like it, but we can put up with it. A non-significant difference means that we have failed to show that something, such as a difference or relationship, exists, but we do not conclude that the thing does not exist. At least, we should not conclude this if we understand statistics. Hence we cannot be misled by such methods, though we can miss things. They are called conservative. P values which are too small lead us to conclude that there is strong evidence that the thing exists, when in fact there is no such thing. Thus we may end up knowing something which ain't so. If a statistician has to be wrong, he/she wants to be wrong in the conservative direction, rather like certain Labour party politicians. How big is the effect? The magnitude of the effect of clustering is measured by the design effect, Deff, given by the following: Deff = 1 + (m - 1)xICC where m is the number of observations in a cluster and ICC is the intra-cluster correlation coefficient. The ICC is the correlation between pairs of subjects chosen at random from the same cluster. It is usually quite small, 0.04 is a typical figure. This was the median ICC reported in the review by Eldridge et al. (2003). If m=1, cluster size one, in other words, no clustering, then Deff=1, otherwise Deff will exceed 1. We can use this in two ways. In design, if we estimate the required sample size ignoring clustering, we must multiply it by the design effect to get the sample size required for the clustered sample. Alternatively, we can say that if the sample size is estimated ignoring the clustering, the clustered sample has the same power as for a simple sample of size equal to what we get if we divide our sample size by the design effect. In analysis, if we analyse the data as if there were no clusters, the variances of the estimates must be multiplied by Deff, hence the standard error must be multiplied by the square root of Deff. From this formula, we can see that clustering may have a large effect if the ICC is large OR if the cluster size is large. Only one of these conditions need be met. For example, if the ICC is 0.001, a very small correlation, and the cluster size is 500, the design effect will be 1 + (500-1)x0.001 = 1.5 and we would need to increase the sample size by 50% to achieve the same power as an unclustered trial. In addition, we need to estimate variances both within and between clusters. If the number of clusters is small, the between clusters variance will have few degrees of freedom and we will be using the t distribution in inference rather than the Normal. This too will cost in terms of power. A study where the cluster size is small, there are a large number of clusters, and the ICC is small will have a design effect close to one and it will have little effect if the clustering is ignored. For example, in a randomised controlled trial of the effects of coordinating care for terminally ill cancer patients (Addington-Hall et al., 1992), 554 patients were randomised by GP. There were about 200 GPs whose patients might be eligible for the study, and so most clusters had only a few patients. I decided for simplicity that the person analysing the trial could ignore the clustering and so did not raise the issue. Possible methods of analysis. There are several possible approaches to get a valid statistical analysis. One possible analysis which should be correct is to find the means for the four clusters and carry out a two-sample t test using these four means only. When I did this for my 1000 simulation runs, I got 53, 5.3% to be significant, and 14, 1.4% to be highly significant, very close to what we would expect from a valid test. There are several approaches which can be used to allow for clustering. The easiest is to calculate a summary statistic for each cluster. This is usually a mean for a continuous outcome or a proportion for a dichotomous outcome. This approach has the great advantage of being simple, but it cannot allow for individual covariates. We can also: - adjust standard errors using the design effect - an approximation.
- robust variance estimates
- general estimating equation models (GEEs)
- multilevel modelling
- Bayesian hierarchical models
- others
I do not wish to go into any of these in this talk. As far as I am concerned, any method which takes into account the clustering will be a vast improvement compared to methods which do not. A survey of papers There have been several reviews of published cluster randomised trials. Problems of identifying trials, e.g. Donner et al. (1990), Simpson et al. (1995), Puffer et al., (2003), and Isaakidis and Ioannidis (2003). All but Puffer et al. (2003) reported that very few trials had sample size calculations which included clustering and about half took clustering into account in analysis, fewer in the African studies reported by Isaakidis and Ioannidis (2003). Puffer et al. (2003) reported recent (1997-2002) trials in British Medical Journal, Lancet, and New England Journal of Medicine. They did not mention any trials which failed to take clustering into account. However, they did have some where clustering was ignored in the analysis. My own review of their trials as listed on the BMJ website found 3 out of 36. Table 1. Some reviews of published cluster randomised trials Authors Source Years Clustering allowed for in sample size Clustering allowed for in analysis Donner et al. (1990) 16 non-therapeutic intervention trials 1979 - 1989 <20% <50% Simpson et al. (1995) 21 trials from American Journal of Public Health and Preventive Medicine 1990 - 1993 19% 57% Isaakidis and Ioannidis (2003) 51 trials in Sub-Saharan Africa 1973 - 2001 (half post 1995) 20% 37% Puffer et al. (2003) 36 trials in British Medical Journal, Lancet, and New England Journal of Medicine 1997 - 2002 56% 92% Eldridge et al. (2003) 152 trials in primary health care 1997 - 2000 20% 59% To identify cluster randomised trials we have to read the trials. We cannot tell from title, keywords, or abstract. The problem papers are those where the authors are not aware of clustering and do not mention it. My strategy was to choose some journals likely to contain cluster randomised trials, such as the British Medical Journal, Lancet, Journal of the Royal College of General Practitioners, etc., and scan some likely years (1983, 1993, 2003) for cluster randomised trials. I decided to start with the British Medical Journal and scan one volume (six months) for each of these years. The yield was much lower than I anticipated. I therefore increased the search to the full year and added 1988 and 1998. References for all the papers found are given in the Appendix. The results are shown in Table 2. Table 2. Result of a search for cluster randomised trials in the British Medical Journal Year Vol Trials Clustering ignored Important? 2003 326-7 9 0 0 1998 316-7 4 1(?) 1 1993 306-7 4 3 2 1988 296-7 0 0 0 1983 286-7 1 1 1 Papers for 2003 go up 8th November. The query is because the authors stated that 'Univariate comparisons were calculated by t test and chi-squared analysis. The role of potential covariates was explored using linear regression specified as a two level model (practice and individual) using the software package MLn.' (Wright et al., 1998). I could find no multilevel modelling in the paper, but a lot of t and chi-squared tests. This was a trial of community based management in failure to thrive by babies. 38 primary care teams were randomly allocated to intervention or control and all children identified in the practice were offered the same intervention, so clearly cluster should be taken into account. Russell et al. (1983) investigated the effect of nicotine chewing gum as an adjunct to general-practitioners advice against smoking. Subjects were 'assigned by week of attendance (in a balanced design) to one of three groups (a) non-intervention controls (b) advice and booklet (c) advice and booklet plus the offer of nicotine gum. There were 6 practices, with recruitment over 3 weeks, one week to each regime. The study was analysed by chi-squared tests. As there were 1938 subjects in 18 clusters, clustering should have been taken into account. Rink et al. (1993) investigated the impact of introducing near patient testing for standard investigations in general practice. 12 practices were used, and some given the equipment and some not in a cross-over design. Analysis used paired t tests, unpaired t tests, odds ratios, ratios of proportions with confidence intervals, and chi-squared tests. Yes, they were at St. George's and just along the corridor from myself and in the same department as Sally Kerry. In a trial of clinical guidelines to improve general-practice management and referral of infertile couples, Emslie et al. (1993) randomised 82 general practices in Grampian region and studied 100 couples in each group. However, the main outcome measure was whether the general practitioner had taken a full sexual history and examined and investigated both partners appropriately, so the GP should quite definitely be the unit of analysis here. The trial where I judged ignoring clustering to be unimportant had many very small clusters. Wetsteyn and Degeus (1993) compared 3 regimens for malaria prophylaxis in travellers to Africa. Members of one family were allocated to one regimen and the results analysed using a chi-squared test. Many methods were used to analyse trials where the authors were aware of the importance of clustering (Table 3). Some authors used more than one method. Table 3. Methods used to adjust for clustering in a survey of the British Medical Journal Method Papers Summary statistics for cluster Coulthard et al. (2003), Meyer et al. (2003), Modell et al. (1998), Wyatt et al. (1998) Chi-squared test adjusted for cluster randomisation. Meyer et al. (2003) Mixed model anova Elley et al. (2003), Nutbeam et al. (1993) Generalised estimating equations Christian et al. (2003), English et al. (2003), Glasgow et al. (2003), Toroyan et al. (2003) Conditional logistic regression Coulthard et al. (2003) "survey" commands in Stata 7.0 Smeeth et al. (2003) Corrected for clustering using Stata Kinmonth et al. (1998), Moore et al. (2003) 95% confidence intervals using a method appropriate for cluster randomised trials Meyer et al. (2003) Conclusions - The effects of clustering can be large, inflating Type I errors.
- This may not be obvious to researchers, even to statisticians. (Quandoque bonus dormitat Homerus) (Even the worthy Homer sometimes nods) (Even the greatest get it wrong).
- There are many ways to allow for clustering.
- The number of cluster randomised trials published has increased greatly.
- The effects of clustering have often been ignored.
- The situation has improved in the British Medical Journal.
- Perhaps statistician pressure works.
Recommendations - Keep up the pressure.
- Extend to specialist journals.
- Extend to all studies where unit of analysis is doubtful:
- Body parts in clinical studies (eyes, teeth, etc.).
- Laboratory studies.
|


 发表于 2007-7-11 13:55:26
发表于 2007-7-11 13:55:26